如何把银行对账单变成干净的 Excel 表格——再也不用一行行手动录入
银行对账单是最难数字化的文档之一:每家银行的版式都不一样,表格跨页断开,一个看错的负号就能让整套对账作废。本文教你如何把它们提取成干净的 Excel、CSV 或 JSON。
- tutorial
- bank statements

随便问哪位记账人员周一早上是怎么过的,你听到的多半是同一套仪式:打开一摞 PDF 银行对账单,开始一行行敲字。日期、摘要、金额、余额。一行接一行,一份接一份,一个客户接一个客户。对一家要处理十几个账户的事务所来说,每个月都要花去大半天时间,把电脑生成这份 PDF 时就已经读过一遍的数字,重新誊抄一遍。
让人抓狂的不是量大,而是这些数据在银行生成它的那一刻本就是结构化的——结果却被压平成一套页面版式,如今还得靠人去手动逆向还原。
这篇文章会带你把那些数据重新取出来:变成干净的 Excel、CSV 或 JSON,全程不用手动录入。我们会聊聊为什么银行对账单格外难提取、几种常见做法各自的取舍,以及用 Ztract 一步步操作的完整流程——包括那些会变棘手的情况,以及该怎么应对。
为什么银行对账单比看上去更难
发票和收据已经够乱了,但银行对账单是另一个难度层级。原因有几个:
- 每家银行都有自己的版式。 根本没有统一标准。Chase、HSBC、本地信用合作社、互联网银行,各自对列、日期和滚动余额的排布都不一样。你为其中一家搭好的模板,到下一家就完全没用了。
- 表格会跨页延续。 一个月的对账单可能横跨四五页,交易表格中途断开,过了页眉之后再接着往下排。粗糙的提取方式要么把续接的行漏掉,要么把页眉当成数据重复录进去。
- PDF、扫描件、照片各不相同。 从网银下载的对账单是文本型的,干净利落。同一份对账单在网点扫描,或者用手机拍下来,就成了图片——这时你得先做 OCR 才能开始提取,而 OCR 本身又会带来新的错误。
- 那些会毁掉对账的小细节。 一笔借记被写成括号里的
(1,250.00),而不是-1250.00;一个写成03/06的日期,到底是 3 月 6 日还是 6 月 3 日,分不清;货币符号紧贴着数字;还有千位分隔符。每一个都很小,可一旦读错,就会悄无声息地把一张表格搞坏。
任何号称能”直接提取银行对账单”的方案,都得对上面这些一一给出答案。手动作业的烦恼,大多来自这条长长的边缘情况尾巴,而不是那条一切顺利的主路径。
几种常见做法,以及它们各自在哪里失灵
并没有哪一款工具是绝对正确的——这取决于你的处理量,以及对账单种类有多杂。说实话,几种取舍是这样的:
手动录入。 零设置成本,只要你够细心准确率就是百分之百,但完全无法规模化。一个月一份还行,对一家事务所来说根本玩不转。
Excel / Google 表格”导入”。 如果你的银行提供 CSV 导出,那就用它——这是最干净的路径,你根本不需要做任何提取。问题在于,人们实际收到的文档大多是 PDF,而把 PDF 表格粘进 Excel 时,只要版式没有完美对齐到网格,列就会立刻错乱。
基于模板的解析器。 你只需一次性定义好每个字段在页面上的位置。只要每份对账单都长得一模一样,它就又快又便宜。但既然每家银行都不一样,你最后只能为每家银行各建一套模板并不断维护——哪天某家银行调整了版式,又得重建一遍。除非你的对账单高度统一,否则光设置的成本就把省下来的时间吃掉了。
基于 LLM 的提取。 你不用去标记位置,而是用大白话描述你想要的字段,引擎会自动适配每一种版式。这正好直接解决了”每家银行都不一样”的难题,对扫描件和奇怪格式的容忍度也高得多。要付出的代价是:你会想要一款能让你核对结果的工具,因为你信任的是一个模型去读这一页,而不是某个固定的坐标。
最后这一类,正是 Ztract 所处的位置,下面我们就实打实地走一遍。
实操演示:在 Ztract 里把银行对账单变成表格
下面是完整流程,无论你处理的是一份对账单,还是一个装着五十份的文件夹,用的都是同一套。
1. 新建一个项目,定义你想要什么
项目其实就是一个容器,装着相关的文档,以及你要套用在它们身上的 schema。对于银行对账单,你有三种方式来定义这个 schema:
-
从现成的银行对账单 schema 起步,再做调整。这是上手最快的方式——它已经懂得交易日期、摘要、借记/贷记金额和滚动余额这些概念。
-
用大白话描述字段。 例如:
“对每一份对账单,提取账户持有人姓名、账号、对账周期、期初余额和期末余额。然后对每一笔交易,提取日期、摘要、金额(借记为负数)以及滚动余额。”
注意那个括号里的备注——“借记为负数”。就这一句话,便告诉了引擎该如何把
(1,250.00)这样的括号写法,规整成干净的-1250.00,而这恰恰是那种会让模板解析器翻车的边缘情况。 -
从样本推断。 丢进一份有代表性的对账单,让 Ztract 据此为你提议一套 schema。当你还不确定某家银行的对账单包含哪些字段、得先看过一份才知道时,这招很管用。
这里最关键的好处在于,同一套 schema 能跨银行通用。你描述的是你想要的数据,而不是它所处的位置,所以哪怕是一种你从没见过的版式,处理方式也完全一样。
2. 上传对账单
把文件拖进来——PDF、Word、Excel、扫描件或手机照片都行,单个文件最大 500 MB。文本型 PDF 和图片型扫描件都能处理,扫描件只是会先过一遍 OCR。如果你把一个月的对账单存成了多个独立文件,一起传上来就行,schema 会套用到全部文件上。
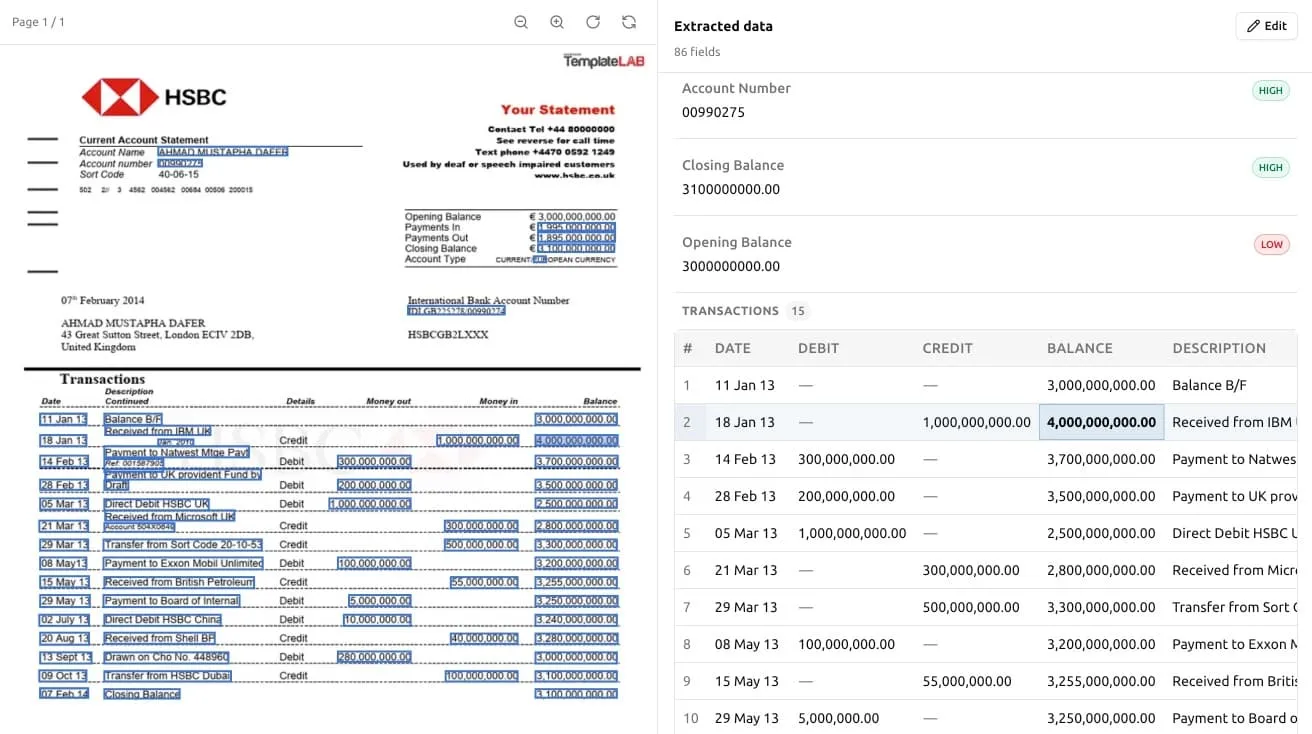
3. 核对与修正——这才是真正要紧的环节
银行对账单的”恶名”就是在这一步坐实的,也是值得放慢脚步的一步。Ztract 会把提取出的每个值,锚定到它在原始页面上的确切位置展示给你:点一下结果里的某个数字,它就会在对账单上高亮出这个数字的来源处。
正是这种左右对照的视图,让核对变得飞快。你不用拿每个数字去和原件逐一重对,只需扫一眼挑出那些看着不对劲的——一笔落到了错误日期上的交易,一个对不上账的滚动余额——然后一键改好。而且因为我们只对提取计费,修正一个值不花你一分钱。 事后的编辑工作是免费的;只有你提取的页数才会从你的页面包里扣减。
对于跨页的多页对账单,这里也是你确认表格在分页处正确拼接起来的地方——确认续接的行都顺利接上了,确认重复出现的页眉没有混进来变成一笔莫须有的交易。
4. 导出
一切看着没问题之后,就导出成 Excel、CSV 或 JSON——单份对账单,或者整个项目一次性导出皆可。从这里它就能直接进入你的对账流程、你的财务软件导入功能,或是这些数字接下来该去的任何地方。
仍然需要人眼把关的情况
我们宁愿坦白告诉你它会在哪里变难,也不愿假装它毫无短板。有几种情况要留意:
- 多币种对账单。 如果一份对账单混用了多种货币,请在你的 schema 里明确写清要按每笔交易记录货币,并在核对环节复查合计金额。别想当然地以为整份文档只有单一货币。
- 严重劣化的扫描件。 一份先传真、再重新扫描、字迹模糊的对账单,对任何人都难读,OCR 也不例外。如果原件你自己肉眼都看不清,那就预备着更仔细地核对。同一份文档换一份更清晰的扫描件,胜过事后再多的修正。
- 合并或不规则的单元格。 有些银行会把摘要单元格跨多行合并,或者把一笔交易拆到两个视觉行里。核对环节正是你揪出这些问题的地方——这也是为什么我们把它做得很快,而不是把提取当成”丢出去就不管”的事。
如果某种我们本该处理好的版式返回了错误结果,我们是真心想看一看——把样本(需要的话先做匿名处理)发邮件到 support@ztract.com,我们会深入排查。大家发给我们的文档,正是引擎不断变好的源泉。
关于敏感财务数据的一点说明
银行对账单大概是世上最敏感的文档之一,所以有必要把话说清楚:我们不会用你上传的文档来训练模型——既不训练我们自己的引擎,也不训练我们经手调用的第三方 LLM。我们使用的商业 API 都明令禁止用提交的数据做训练,我们依靠的正是这些承诺。当你删除一份对账单时,它会立即从活动存储中消失,并在 14 天内从备份中清除。完整的说明请见我们的隐私政策和数据处理协议。
拿你自己的对账单试一试
要判断这套流程是否契合你的工作方式,最快的办法就是拿一份你原本要手动录入的对账单跑一遍。新账户可获得 30 页免费额度,无需信用卡——足够你把几份真实的对账单从头到尾提取一遍,亲眼看看输出有多干净。
如果你的对账单处理量很大,又愿意就哪里好用、哪里不好用给我们一些坦诚的反馈,欢迎联系我们——我们正在引入早期用户,并围绕大家真正头疼的文档,来打磨我们接下来要做的东西。银行对账单就排在那张清单的前列。
想了解更多关于银行对账单提取的内容,请查看我们的使用场景页面。