은행 거래내역서를 손으로 입력하지 않고 깔끔한 스프레드시트로 바꾸는 법
은행 거래내역서는 디지털화하기 가장 까다로운 문서 중 하나입니다. 은행마다 레이아웃이 제각각이고, 표가 여러 페이지에 걸쳐 이어지며, 마이너스 부호 하나만 잘못 읽어도 정산 전체가 틀어집니다. 이런 거래내역서를 깔끔한 Excel, CSV, JSON으로 추출하는 방법을 소개합니다.
- tutorial
- bank statements

회계 담당자에게 월요일 아침이 어떤지 물어보면, 표현은 달라도 결국 같은 의식(儀式)을 듣게 됩니다. PDF 은행 거래내역서 한 무더기를 열어 놓고, 입력을 시작하는 것이죠. 날짜, 적요, 금액, 잔액. 한 줄 한 줄, 내역서 하나하나, 거래처 하나하나. 계정을 열두 개쯤 다루는 사무소라면, 매달 거의 하루를 통째로 컴퓨터가 PDF를 만들 때 이미 한 번 읽었던 숫자를 다시 옮겨 적는 데 쓰는 셈입니다.
답답한 건 양이 아닙니다. 문제는 그 데이터가 은행이 만들어 낼 때만 해도 이미 구조화되어 있었다는 점입니다. 그걸 페이지 레이아웃 속에 납작하게 눌러 놓았고, 이제 사람이 손으로 거꾸로 풀어내야 하는 거죠.
이 글에서는 그 데이터를 다시 꺼내는 방법, 즉 수작업 입력 없이 깔끔한 Excel, CSV, JSON으로 되살리는 방법을 단계별로 살펴봅니다. 은행 거래내역서가 왜 유독 추출하기 어려운지, 흔히 쓰는 방식들의 장단점은 무엇인지, 그리고 Ztract를 이용한 실제 작업 흐름을 까다로워지는 경우와 그 대처법까지 포함해 차근차근 짚어 보겠습니다.
은행 거래내역서가 보기보다 까다로운 이유
송장이나 영수증도 지저분하지만, 은행 거래내역서는 차원이 다른 난도입니다. 몇 가지 이유가 있습니다.
- 은행마다 레이아웃이 제각각입니다. 표준이라는 게 없습니다. Chase, HSBC, 동네 신용협동조합, 그리고 네오뱅크가 각자 다른 방식으로 열, 날짜, 누적 잔액을 배치합니다. 한 은행에 맞춰 만든 템플릿은 다음 은행에서는 쓸모가 없습니다.
- 표가 여러 페이지에 걸쳐 이어집니다. 한 달치가 네다섯 페이지에 걸쳐 있을 수 있고, 거래 표가 중간에 끊겼다가 페이지 머리글 다음에 다시 이어지기도 합니다. 단순한 추출 방식은 이어지는 행을 누락하거나, 머리글을 데이터로 잘못 중복 인식합니다.
- PDF냐, 스캔이냐, 사진이냐. 인터넷 뱅킹에서 내려받은 내역서는 텍스트 기반이라 깔끔합니다. 같은 내역서를 지점에서 스캔하거나 휴대폰으로 찍으면 이미지가 되고, 이제는 무엇이든 추출하기 전에 OCR이 필요합니다. 그리고 OCR은 그 나름의 오류를 만들어 냅니다.
- 정산을 망가뜨리는 사소한 것들. 출금이
-1250.00이 아니라 괄호를 씌운(1,250.00)로 표시된 경우.03/06처럼 3월 6일인지 6월 3일인지 헷갈리는 날짜. 숫자에 딱 붙어 있는 통화 기호. 천 단위 구분 기호. 하나하나는 사소하지만, 잘못 읽히면 그때마다 조용히 스프레드시트를 오염시킵니다.
“은행 거래내역서를 그냥 추출해 드립니다”라고 내세우는 어떤 방식이든, 이 모든 경우에 대한 답을 갖고 있어야 합니다. 수작업의 괴로움은 대부분 정상적인 경우가 아니라 길게 늘어선 예외 사례에서 나옵니다.
흔히 쓰는 방식들, 그리고 각각이 한계에 부딪히는 지점
정답이 되는 단 하나의 도구는 없습니다. 처리량이 얼마인지, 그리고 내역서가 얼마나 제각각인지에 따라 달라집니다. 솔직하게 장단점을 짚어 보면 이렇습니다.
손으로 입력하기. 준비 작업이 전혀 필요 없고, 꼼꼼하다면 정확도는 완벽하지만, 전혀 확장되지 않습니다. 한 달에 내역서 한 장이면 괜찮습니다. 사무소 규모라면 애초에 선택지가 못 됩니다.
Excel / Google Sheets “가져오기”. 거래 은행이 CSV 내보내기를 지원한다면 그걸 쓰세요. 그게 가장 깔끔한 길이고, 추출 자체가 아예 필요 없습니다. 문제는 사람들이 실제로 받는 문서 _대부분_이 PDF라는 점입니다. PDF 표를 Excel에 붙여 넣으면 레이아웃이 완벽한 격자가 아닌 순간 열이 뒤죽박죽 엉켜 버립니다.
템플릿 기반 파서. 각 필드가 페이지의 어느 위치에 있는지 한 번 정의해 두는 방식입니다. 모든 내역서가 똑같이 생겼다면 빠르고 저렴합니다. 하지만 은행마다 다르기 때문에, 결국 은행마다 템플릿을 만들고 관리해야 하고, 은행이 레이아웃을 살짝 바꾸는 날 다시 만들어야 합니다. 내역서가 아주 일정하지 않은 한, 준비에 드는 비용이 절약한 시간을 잡아먹습니다.
LLM 기반 추출. 위치를 표시하는 대신, 원하는 필드를 일상적인 언어로 설명하면 엔진이 각 레이아웃에 맞춰 적응합니다. “은행마다 다르다”는 문제를 정면으로 해결하고, 스캔본이나 이상한 서식에도 훨씬 너그럽습니다. 단점이라면, 고정된 좌표가 아니라 모델이 페이지를 읽는다고 신뢰하는 것이므로, 출력 결과를 직접 검증할 수 있게 해 주는 도구를 골라야 한다는 점입니다.
Ztract는 바로 이 마지막 범주에 속합니다. 그러니 이제 구체적으로 살펴보겠습니다.
실제 작업: Ztract에서 은행 거래내역서를 스프레드시트로
내역서 한 장이든 쉰 장이 든 폴더든 똑같이 쓰는 전체 흐름입니다.
1. 프로젝트를 만들고 원하는 것을 정의하기
프로젝트는 관련 문서들과 거기에 적용할 스키마를 담는 그릇일 뿐입니다. 은행 거래내역서의 경우, 스키마를 정의하는 방법은 세 가지입니다.
-
이미 만들어진 은행 거래내역서 스키마에서 시작해 조정하는 방법. 가장 빠른 출발점입니다. 거래 날짜, 적요, 출금/입금 금액, 누적 잔액을 이미 알고 있으니까요.
-
필드를 일상적인 말로 설명하는 방법. 예를 들면 이렇습니다.
“각 내역서에서 예금주명, 계좌번호, 명세 기간, 기초 잔액, 기말 잔액을 추출해 줘. 그리고 거래 한 건마다 날짜, 적요, 금액(출금은 음수로), 누적 잔액을 추출해 줘.”
괄호 안의 표현 — “출금은 음수로” — 을 눈여겨보세요. 이 한 줄짜리 지시가 엔진에게
(1,250.00)같은 괄호 표기를 깔끔한-1250.00으로 정규화하는 방법을 알려 줍니다. 바로 이런 예외 사례가 템플릿 파서를 탈선시키는 종류의 문제입니다. -
샘플에서 추론하는 방법. 대표적인 내역서 한 장을 넣어 두면 Ztract가 그것을 보고 스키마를 제안해 줍니다. 특정 은행이 어떤 필드를 담고 있는지 직접 한 장 보기 전에는 확신이 서지 않을 때 유용합니다.
여기서 핵심 장점은 같은 스키마가 은행을 가리지 않고 작동한다는 점입니다. 데이터가 놓인 위치가 아니라 원하는 데이터 자체를 설명하는 것이므로, 한 번도 본 적 없는 레이아웃도 똑같이 처리됩니다.
2. 내역서 업로드하기
파일을 끌어다 놓으세요. PDF, Word, Excel, 스캔본, 휴대폰 사진까지, 파일당 최대 500MB입니다. 텍스트 기반 PDF든 이미지 기반 스캔본이든 모두 작동하며, 스캔본은 그저 먼저 OCR 처리될 뿐입니다. 한 달치 내역서가 여러 개의 개별 파일로 있다면 함께 업로드하세요. 스키마가 전부에 적용됩니다.
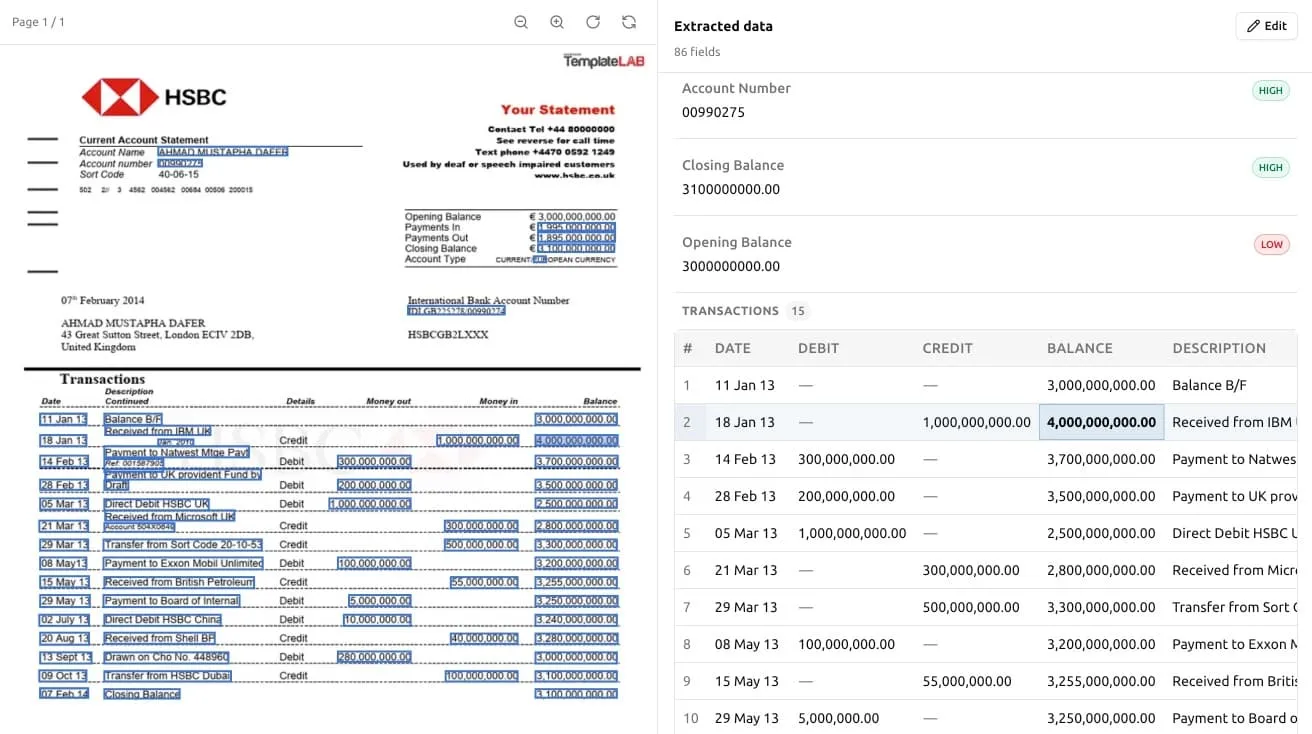
3. 검토하고 수정하기 — 정말 중요한 단계
은행 거래내역서가 까다롭다는 평판을 얻는 지점이 바로 여기이고, 시간을 들여 천천히 할 가치가 있는 단계입니다. Ztract는 추출된 각 값을 원본 페이지의 정확한 위치에 고정해 보여 줍니다. 결과에서 숫자 하나를 클릭하면 내역서의 어느 부분에서 나온 값인지 강조 표시됩니다.
이 나란히 보기 화면이 검증을 빠르게 만들어 줍니다. 모든 수치를 원본과 일일이 다시 대조하는 대신, 어딘가 어긋나 보이는 것 — 엉뚱한 날짜에 잡힌 거래, 계산이 맞지 않는 누적 잔액 — 만 훑어보고 클릭 한 번으로 고치면 됩니다. 그리고 저희는 추출에 대해서만 요금을 매기기 때문에, 값을 수정하는 데는 비용이 들지 않습니다. 사후 편집 작업은 무료이며, 한도에서 차감되는 건 추출한 페이지뿐입니다.
여러 페이지짜리 내역서라면, 이곳이 페이지 경계를 넘나들며 표가 제대로 이어 붙었는지 확인하는 자리이기도 합니다. 이어지는 행이 빠짐없이 들어왔는지, 반복되는 페이지 머리글이 유령 거래처럼 슬쩍 끼어들지는 않았는지 말이죠.
4. 내보내기
결과가 제대로 보이면 Excel, CSV, JSON으로 내보내세요. 내역서 한 장만, 또는 프로젝트 전체를 한 번에 내보낼 수 있습니다. 거기서부터는 곧장 정산 업무로, 회계 소프트웨어의 가져오기 기능으로, 또는 숫자가 가야 할 다음 어디로든 흘러갑니다.
그래도 사람의 눈이 필요한 경우들
어렵지 않은 척하기보다, 어디가 어려운지 솔직히 말씀드리는 편이 낫겠습니다. 몇 가지 주의할 상황이 있습니다.
- 다중 통화 내역서. 한 내역서에 여러 통화가 섞여 있다면, 거래 건마다 통화를 잡아내도록 스키마에서 명시하고, 검토 단계에서 합계를 다시 한번 확인하세요. 문서 전체가 단일 통화라고 가정하지 마세요.
- 심하게 손상된 스캔본. 팩스로 보냈다가 다시 스캔한, 인쇄가 흐릿한 내역서는 OCR을 포함해 누구에게나 읽기 어렵습니다. 원본이 당신 눈에도 알아보기 힘들다면, 더 꼼꼼히 검증할 각오를 하세요. 같은 문서를 더 깨끗하게 스캔한 한 장이, 사후에 아무리 많이 손보는 것보다 낫습니다.
- 병합되거나 불규칙한 셀. 어떤 은행은 적요 셀을 여러 줄에 걸쳐 병합하거나, 거래 한 건을 시각적으로 두 행에 나눠 놓습니다. 검토 단계가 바로 이런 것들을 잡아내는 자리이고, 그래서 저희는 추출을 한 번 던지고 잊는 식으로 다루는 대신 검토를 빠르게 할 수 있도록 만들었습니다.
저희가 마땅히 처리해야 할 레이아웃이 잘못 나온다면, 정말로 그 사례를 보고 싶습니다. 샘플을 (필요하면 익명화해서) support@ztract.com으로 보내 주시면 저희가 파고들겠습니다. 사람들이 보내 주시는 문서가 곧 엔진이 더 나아지는 길입니다.
민감한 금융 데이터에 관한 한마디
은행 거래내역서는 문서 중에서도 가장 민감한 축에 속하니, 분명히 해 두는 게 좋겠습니다. 저희는 업로드하신 문서로 모델을 학습시키지 않습니다. 저희 자체 엔진도, 저희가 거쳐 가는 제3자 LLM도 마찬가지입니다. 저희가 사용하는 상용 API는 제출된 데이터로 학습하는 것을 금지하고 있으며, 저희는 그 약정에 기대고 있습니다. 내역서를 삭제하면 활성 저장소에서는 즉시, 백업에서는 14일 이내에 사라집니다. 전체 내용은 개인정보 처리방침과 데이터 처리 계약에서 확인하실 수 있습니다.
직접 보유한 내역서로 시험해 보세요
이 방식이 당신의 업무 흐름에 맞는지 가장 빠르게 아는 길은, 원래라면 손으로 입력했을 내역서 한 장에 실제로 돌려 보는 것입니다. 신규 계정에는 신용카드 없이 무료 30페이지가 제공됩니다. 실제 내역서 몇 장을 처음부터 끝까지 추출해 보고 결과가 얼마나 깔끔한지 확인하기에 충분한 양입니다.
내역서를 대량으로 처리하시고, 무엇이 잘되고 무엇이 안 됐는지 솔직한 피드백을 나눠 주실 의향이 있다면 연락 주세요. 저희는 지금 초기 사용자를 모시고 있고, 사람들이 실제로 씨름하는 문서들을 중심으로 다음에 만들 것을 빚어 가고 있습니다. 은행 거래내역서는 그 목록의 거의 맨 위에 있습니다.
은행 거래내역서 추출에 관해 더 알아보려면 저희 사용 사례 페이지를 확인해 보세요.