设计你的 schema
Schema 就是你对每份文档想抽出什么的声明。三种定义方式 —— 挑一个你想数据的方式最接近的就行。
更新于:
Schema 是什么?
Ztract 里的 schema,就是你希望拿回来的数据长什么样。它是一份 字段清单,每个字段有名字、类型和可选的结构(比如「明细行」是一个 对象数组,每个对象有描述、数量、单价)。引擎会按 schema 读每份上传 的文档,把命中的值返回给你,并锚定到它在源文档页面上出现的位置。
Schema 归属于项目。一个项目 = 一个 schema = 这个项目里所有文档 共用一份一致的输出结构。如果你有多种文档类型,通常就一种类型建一个项目。
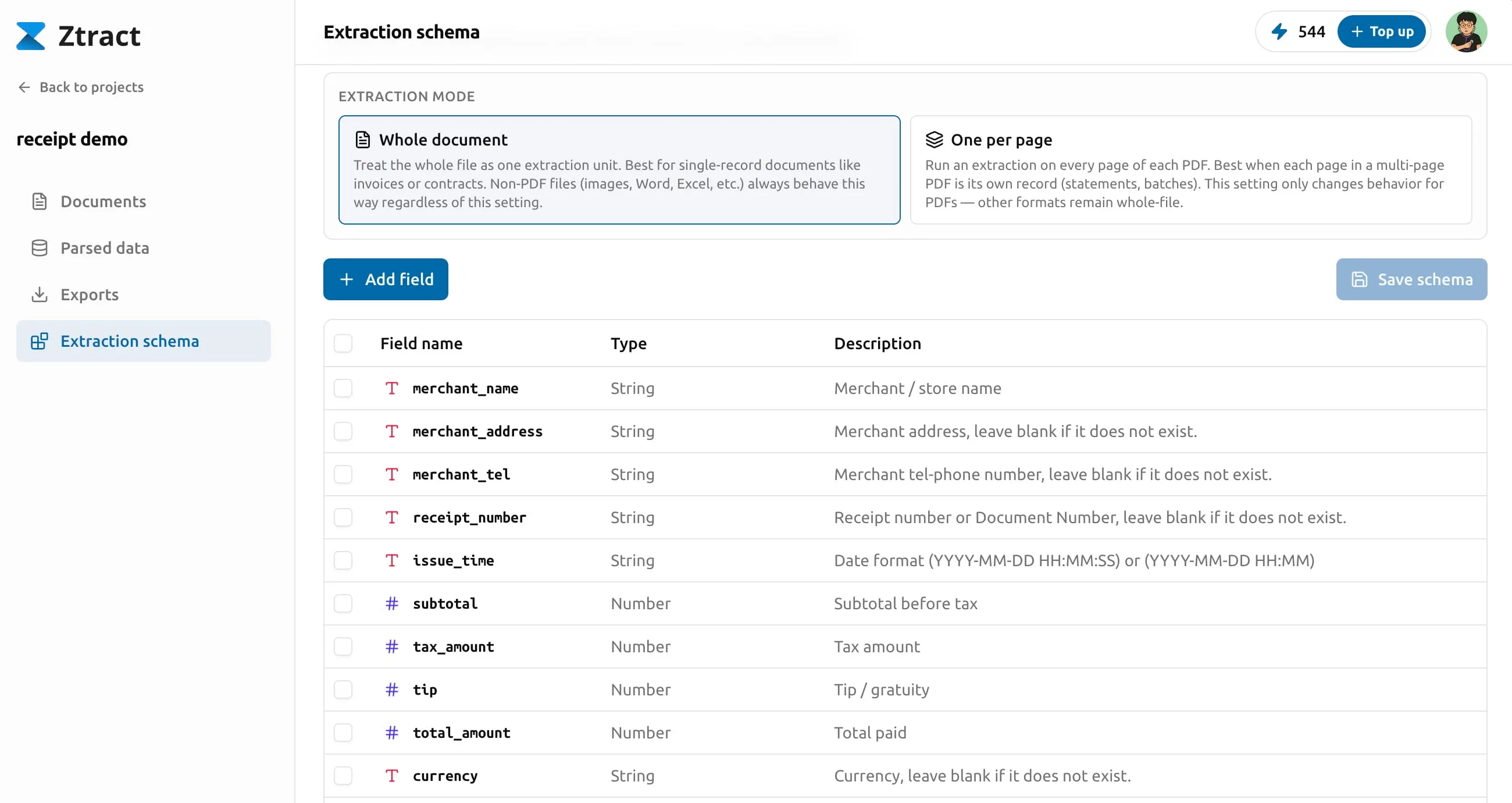
字段类型与结构
每个字段都属于六种类型之一:
- string —— 自由文本。姓名、地址、自由描述。
- number —— 小数值。金额、百分比、尺寸。
- integer —— 整数。数量、计数。
- enum —— 必须从你定义的固定列表里取值的字符串。 适合那些取值天然受限的字段 —— 订单状态、支付方式、币种代码。
- object —— 一组嵌套字段。当一个东西天然带子属性时用它
(比如一个
address,下面有street/city/zip)。 - array —— 可重复的列表。元素可以是基础类型(简历里的「技能」), 也可以是对象(发票里的「明细行」)。
Object 和 array 结构可以嵌套,最多三层。 现实世界里大部分文档两层就够用 —— 发票的明细行、合同的签署方 —— 三层是给那些确实需要更深结构的少数场景留的天花板。
方式一 —— 从模板开始
Ztract 为发票、收据、合同、身份证件等常见文档类型准备了 现成模板。每份模板都是一份可用的 schema,带字段名、类型, 以及(用得上的话)嵌套结构。它们基于真实文档构建,不是教科书 里的理想形态。模板目录会本地化 —— 当你的 dashboard 语言设为英文时, 你看到的是英文命名的模板;切到中文、日本語等等,列表也会跟着变。
什么时候最合适。 你的文档类型刚好落在一个明确的类别里, 而且下游工具期望的也是标准结构 —— 比如「把发票导进 NetSuite」 或「把报销收据导进 Concur」。两下点击就能拿到一份可用的 schema。
怎么自定义。 打开模板,把任意字段改成你团队习惯的叫法, 删掉用不上的字段,加上你工作流里特有的自定义字段。保存 schema, 就能开始上传文档了。

方式二 —— 用大白话描述
如果没有合适的模板,那就直接写你要什么。打一两句话描述这些字段, Ztract 会根据你的描述起草一份完整的 schema。你确认或微调一下就能保存。
示例 prompt。 「对每份采购订单,抽出 PO 号、供应商名称和地址、签发日期、交付 日期、明细行(含 SKU、描述、数量、单价),以及订单合计。另外标记 出这份 PO 是否被标为加急。」
引擎会给出类似这样的结果:
po_number—— stringvendor——{ name, address }issue_date—— datedelivery_date—— dateline_items—— array of{ sku, description, quantity, unit_price }order_total—— numberrush_order—— boolean
什么时候最合适。 你心里很清楚自己要什么,但手上没有一份能 拿来传的标准样本。或者你的文档类型小众到没有模板对得上。
方式三 —— 从样本文档里推断
传一份样本文档上来,引擎会读它,并提议一份带字段名、类型和它在 里面发现的嵌套结构的 schema。你再调整:去掉不关心的字段、加上 样本里没有但你需要的字段、把类型收紧。
什么时候最合适。 不亲眼看一份实际文档你都不知道里面有哪些 字段 —— 这种情况在医检报告(每家化验所打印的项目都不一样)、 定制起草的合同、以及一次性的供应商表单里很常见。当文档上某个 字段名比较奇怪、你想让引擎给一个规范化的命名建议时,这种方式 也很好用。
创建之后再调整 schema
你随时可以编辑 schema —— 改字段名、加新字段、改类型、重新组织 嵌套。改动不会影响你已经处理过的文档;如果想拿到新结构的结果, 要在新 schema 下重跑一遍。重跑是要扣费的(见 计费、套餐与退款),所以大部分团队会先在一小 批文档上把 schema 定稿,再大规模处理。
一些刁钻字段的小技巧
- 日期。 不管文档上印的是哪种格式 —— DD/MM/YYYY、Jun 5 2026(2026 年 6 月 5 日)、「Q2 2026」(2026 年第二季度)—— Ztract 都会按你在 schema 里指定的日期格式转换。如果没指定格式,日期会按文档上印的原样返回。
- 金额和币种。 币种会保留原样(€、$、¥、₩ 等等);我们不会 悄悄帮你换算。逐行的税率也会跟它所属的那行绑在一起。
- 嵌套结构。 如果文档本身就有子对象(合同里的当事人、供应商 协议里的付款条款),就在 schema 里用嵌套。输出的 JSON 会保留 这种嵌套;CSV / Excel 会用点号路径铺平。
- 纯字符串数组。 像简历里的「技能」、护照上的「签注」这种 字段,会以字符串数组的形式返回。Dashboard 在并排查看器里会把 数组渲染成表格 —— 一行一个元素,每行都链回它在源文档里的位置。
- Enum 字段。 词汇受限的字段(状态、币种代码、文档分类)最 适合用 enum —— 你把允许的取值定一次,引擎就会严格使用这些值, 而不是冒出「Paid」「paid」「PAID」「Settled」这种五花八门的变体。