スキーマを設計する
スキーマは、各ドキュメントから何を取り出したいかを宣言するものです。定義の方法は 3 通り — 普段からデータをどう捉えているかに合わせてお選びください。
更新日:
スキーマとは何か
Ztract における スキーマ とは、返してほしいデータの形のことです。 フィールド名、型、必要に応じて構造(たとえば「明細行」は description、 quantity、unit_price を持つオブジェクトの配列、など)の一覧で構成されます。 エンジンはアップロードされた各ドキュメントをこのスキーマに照らして読み取り、 該当する値を、元ページのどこに現れたかの位置情報とともに返します。
スキーマはプロジェクト内に存在します。1 プロジェクト = 1 スキーマ = そのプロジェクト内のすべてのドキュメントに共通する 1 つの出力フォーマット です。複数のドキュメント種別を扱う場合は、種別ごとにプロジェクトを 1 つ 作成するのが一般的です。
フィールドの型と構造
各フィールドは次の 6 つの型のいずれかを持ちます。
- string — 自由テキスト。氏名、住所、自由記述の説明文など。
- number — 小数値。金額、パーセンテージ、寸法など。
- integer — 整数。数量、件数など。
- enum — 定義済みの固定リストから選ばれる文字列。 注文ステータス、支払方法、通貨コードなど、値が カテゴリ的に制約されている項目に使います。
- object — ネストしたフィールドのグループ。対象が本来サブ属性を
持つとき(
street/city/zipを持つaddressなど)に使います。 - array — 繰り返しのリスト。要素はプリミティブ(履歴書の「スキル」) でもオブジェクト(請求書の「明細行」)でも構いません。
オブジェクトと配列の構造は 3 階層まで ネストできます。 実務上のドキュメントの多くは 2 階層で十分です — 請求書の明細行、 契約書の署名者など — 3 階層は本当に必要な稀なケースのための上限です。
方法 1 — テンプレートから始める
Ztract には、請求書、領収書、契約書、身分証など一般的なドキュメント 種別向けに、すぐ使えるテンプレートが用意されています。各テンプレートは フィールド名、型、(該当する場合は)ネスト構造を備えた、動作する スキーマです。教科書的な理想ではなく、実例から作られています。 収録ラインアップはローカライズされており — ダッシュボードの言語が 英語ならば英語名のテンプレートが表示され、中国語や日本語などに 切り替えるとリストもそれに応じて更新されます。
こんなときに最適。 ドキュメントの種別が明確なカテゴリに当てはまり、 後続ツールが標準的な形を期待している場合 — たとえば「請求書を NetSuite に取り込む」「経費領収書を Concur に取り込む」など。 2 クリックで動くスキーマが手に入ります。
カスタマイズの方法。 テンプレートを開き、チームの用語に合わせて 任意のフィールド名を変更し、不要なフィールドを削除し、ワークフロー 固有のカスタムフィールドを追加します。スキーマを保存すれば、 アップロードの準備は完了です。

方法 2 — 自然な英語で説明する
テンプレートが合わないときは、欲しい内容をそのまま書いてください。 フィールドを説明する文を 1〜2 文で入力すると、Ztract がその説明から 完全なスキーマを下書きします。保存前に確認・微調整できます。
プロンプト例。 「For each purchase order, extract the PO number, vendor name and address, issue date, delivery date, line items with SKU, description, quantity, and unit price, and the order total. Also flag whether the PO is marked as a rush order.」
エンジンは次のような出力を生成します。
po_number— stringvendor—{ name, address }issue_date— datedelivery_date— dateline_items— array of{ sku, description, quantity, unit_price }order_total— numberrush_order— boolean
こんなときに最適。 何が必要かは頭の中に明確にあるけれど、 アップロードできる標準的なサンプルがないとき。あるいは、ドキュメント種別が ニッチで適合するテンプレートが存在しないときです。
方法 3 — サンプルドキュメントから推測する
サンプルとなるドキュメントを 1 つアップロードすると、エンジンがそれを 読み取り、見つけたフィールド名、型、ネスト構造を備えたスキーマを提案します。 あとは調整するだけです — 不要なフィールドを削除し、サンプルに含まれて いなかったものを追加し、型を厳密化します。
こんなときに最適。 実物を見るまでどんなフィールドが存在するか 分からないとき — 検査機関ごとに項目構成が異なる医療レポート、 個別に作成された契約書、単発のベンダー書類などでよくあるケースです。 ドキュメント上のフィールド名が独特で、エンジンに正規化された 名前を提案してほしいときにも役立ちます。
作成後にスキーマを調整する
スキーマはいつでも編集できます — フィールド名の変更、新規追加、 型の変更、ネスト構造の再編成。編集はすでに処理済みのドキュメントには 影響しません。新しいスキーマでの形に揃えたい場合は、再実行する必要が あります。再実行は課金対象です(請求、パッケージ、返金 を参照)。そのため、多くのチームはまず小さなバッチでスキーマを確定して から、本格的な処理に進めます。
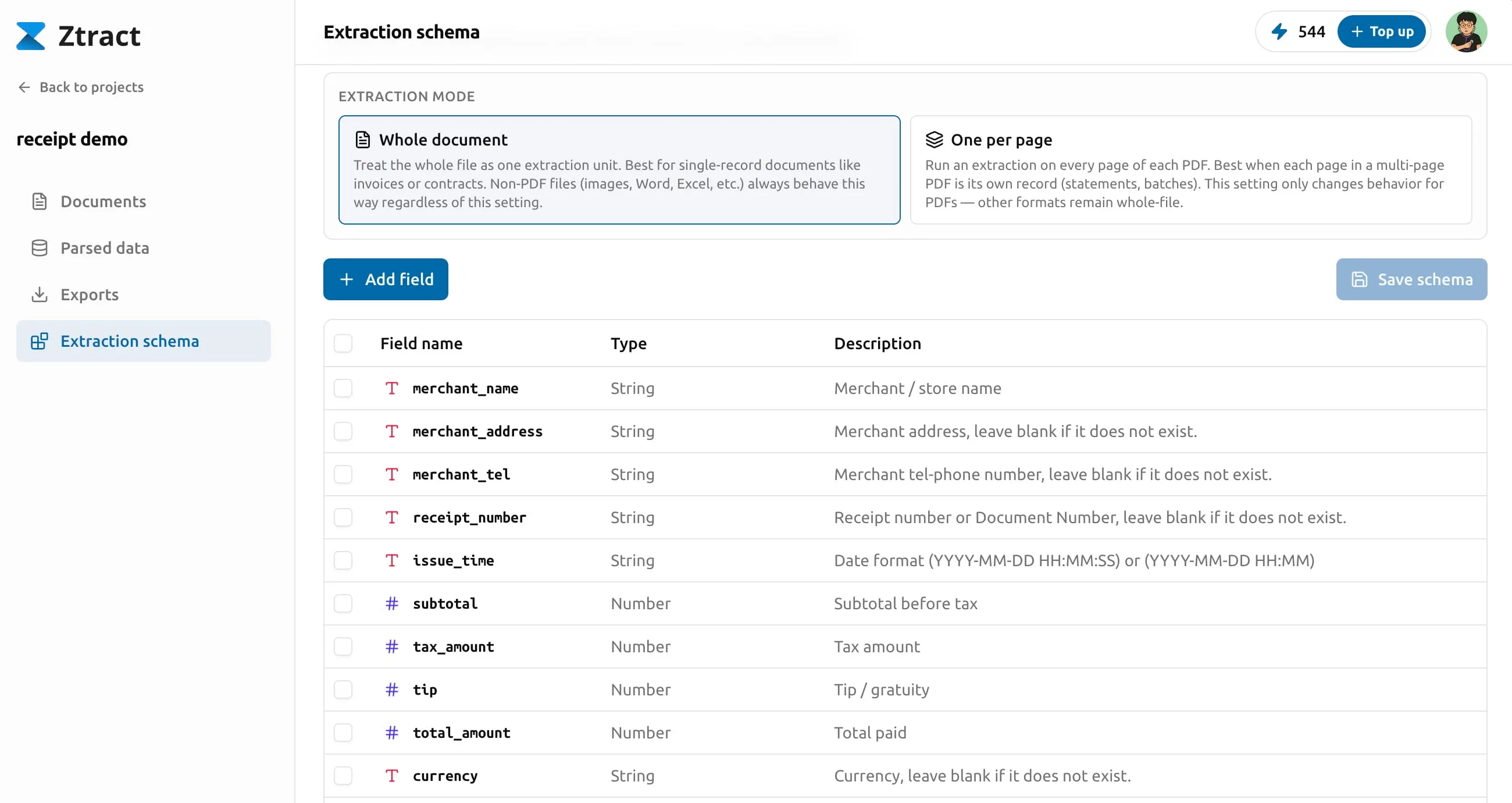
扱いに迷うフィールドのヒント
- 日付。 ドキュメント上の表記がどうであれ — DD/MM/YYYY、Jun 5 2026、 「Q2 2026」など — Ztract はスキーマで指定した日付フォーマットに変換します。 フォーマットを指定しない場合は、印字されたままの形で返されます。
- 金額と通貨。 通貨は元の表記のまま保持されます(€、$、¥、₩ など)。 暗黙の変換は行いません。明細行ごとの税率は、それが属する行に 紐付いたまま保持されます。
- ネストした構造。 ドキュメントが本来サブオブジェクトを持つ場合 (契約書の当事者、ベンダー契約内の支払条件など)は、スキーマでも ネストを使ってください。出力 JSON はそのネストをそのまま反映します。 CSV / Excel ではドット区切りのパスで平坦化されます。
- 文字列だけの配列。 履歴書の「スキル」やパスポートの「裏書」のような フィールドは、文字列の配列として返されます。ダッシュボードの並列 ビューアーでは、その配列を表として表示します — 1 行が 1 項目に対応し、 それぞれが元ドキュメントの該当領域にリンクします。
- enum フィールド。 語彙が限定されたフィールド(ステータス、通貨コード、 ドキュメントクラスなど)は enum として扱うのが最適です — 許可される値を 一度指定すれば、エンジンはそれに従い、「Paid」「paid」「PAID」「Settled」 といったバリエーションを勝手に生み出すことがなくなります。