はじめに
アカウントを作成し、スキーマを定義し、ドキュメントをアップロードすれば、構造化データが返ってきます。5 分以内、開発者は不要です。
更新日:
はじめる前に
インストールするものは何もありません — Ztract は app.ztract.com でブラウザ上で完結します。CLI も SDK もなく、以下の手順で API を組み込む必要もありません。API については正式提供時に専用ページでご案内します。必要なのは、データを 抽出したいドキュメント — PDF、Word ファイル、Excel シート、スキャン、 スマホ写真 — とメールアドレスだけです。
ステップ 1 — アカウントを作成する
app.ztract.com にアクセスしてください。 メールアドレスを入力すると、ワンタイム認証コードをお送りします — 覚えておく パスワードも、別のサインアップフォームも、クレジットカードも必要ありません。 (Google をお使いですか?Continue with Google がメール欄のすぐ下にあります。) ログインすると、アカウントに 30 ページ無料分 が自動で付与されます。 これをエンジンで自由に試していただいて構いません。勝手にプランへ移行させたり、 営業メールでお知らせしたりすることはありません。
ステップ 2 — 最初のプロジェクトを作成する
Ztract の プロジェクト は、同じスキーマを共有する関連ドキュメントの まとまりです。多くのチームは、ドキュメントの種類ごとに 1 プロジェクト — 「仕入先請求書」「経費領収書」「顧客契約書」 — を用意し、加えて 単発の書類用に 1 プロジェクトを持っています。作成できるプロジェクト数に 上限はありません。
ダッシュボードから 「新規プロジェクト」 をクリックし、名前を付け、 開始用のスキーマを選択してください(スキーマの意味は次のステップで 説明します)。
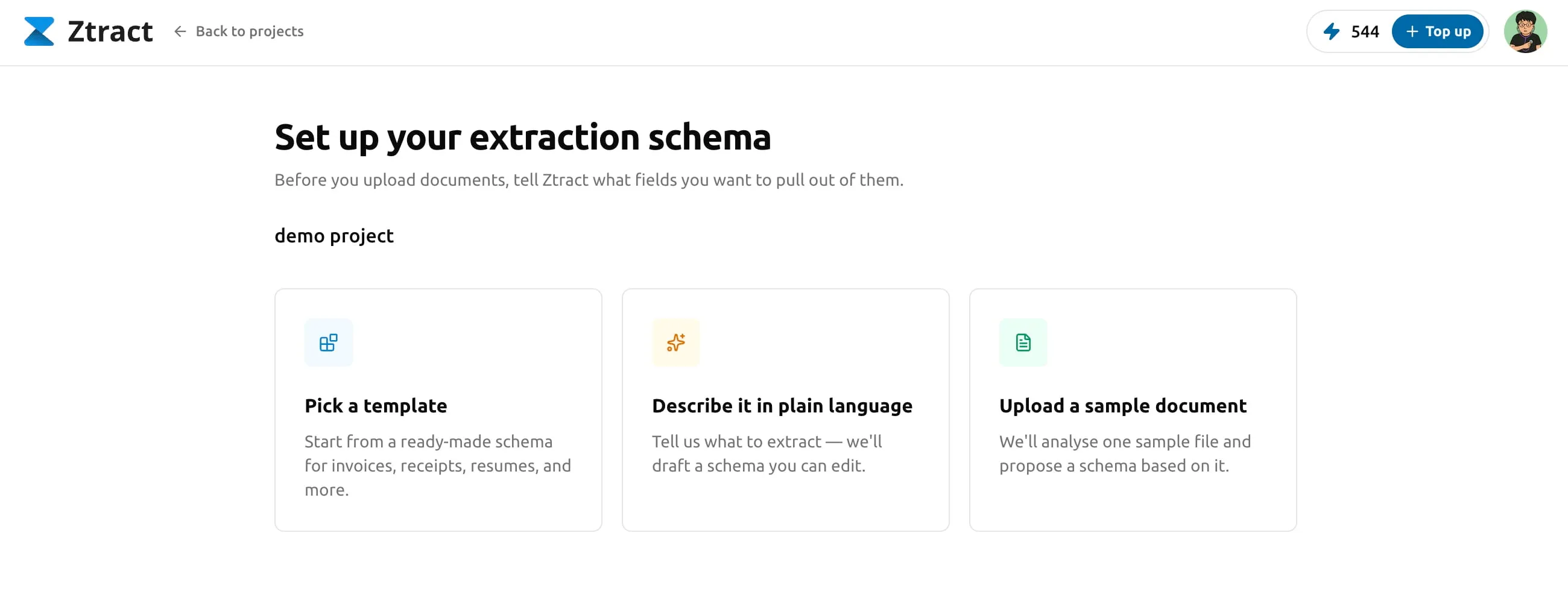
ステップ 3 — スキーマを定義する
スキーマ とは、各ドキュメントから Ztract に取り出してほしいフィールドの 一覧です。請求書なら、請求書番号、仕入先、日付、合計、明細行のテーブルなど。 領収書なら、店舗、日付、商品。パスポートなら、氏名、書類番号、有効期限です。
定義方法は 3 通りあります。
- テンプレートから選ぶ。 請求書、領収書、契約書、身分証など、一般的な ドキュメントタイプ向けのテンプレートを用意しています。1 つクリックし、 チームの用語に合わせてフィールド名を変えたり削除したりして、保存します。
- 自然な英語で説明する。 たとえば 「各請求書から、請求書番号、仕入先、 合計、品目・数量・単価を含む明細行を抽出して」 のように一文で書きます。 エンジンがその説明からスキーマを下書きし、あとは確認・微調整するだけです。
- サンプルドキュメントを投げ込む。 実物を見るまでどんなフィールドが あるか分からない場合は、サンプルを 1 つアップロードしてください。エンジンが 読み取り、適切なフィールド名、型、ネスト構造を備えたスキーマを提案します。 あとはそこから調整します。
スキーマの設計 の記事で、どの方法がどんな場面に 最も向くかを詳しく解説しています。
ステップ 4 — ドキュメントをアップロードする
スキーマを保存したら、プロジェクトの 「ドキュメント」 タブに移動して、
ファイルを 1 つまたは複数ドラッグしてください。Ztract は PDF、Word
(.doc / .docx)、Excel(.xls / .xlsx)、PowerPoint
(.ppt / .pptx)、HTML(.mhtml を含む)、TXT、CSV、RTF、OFD、
さらに JPG、PNG、WebP、TIFF、BMP の画像を受け付けます — 1 ファイル最大
500 MB です。サイズ上限、一括アップロード、ファイルが失敗したときの
挙動について詳しくは、ドキュメントのアップロード
の記事をご覧ください。
ダッシュボードはファイルが届いた順に処理を進め、進捗をリアルタイムで 表示します。1 ページの書類なら通常数秒で完了します。50 ページの契約書は もう少しかかります。
ステップ 5 — レビューと修正
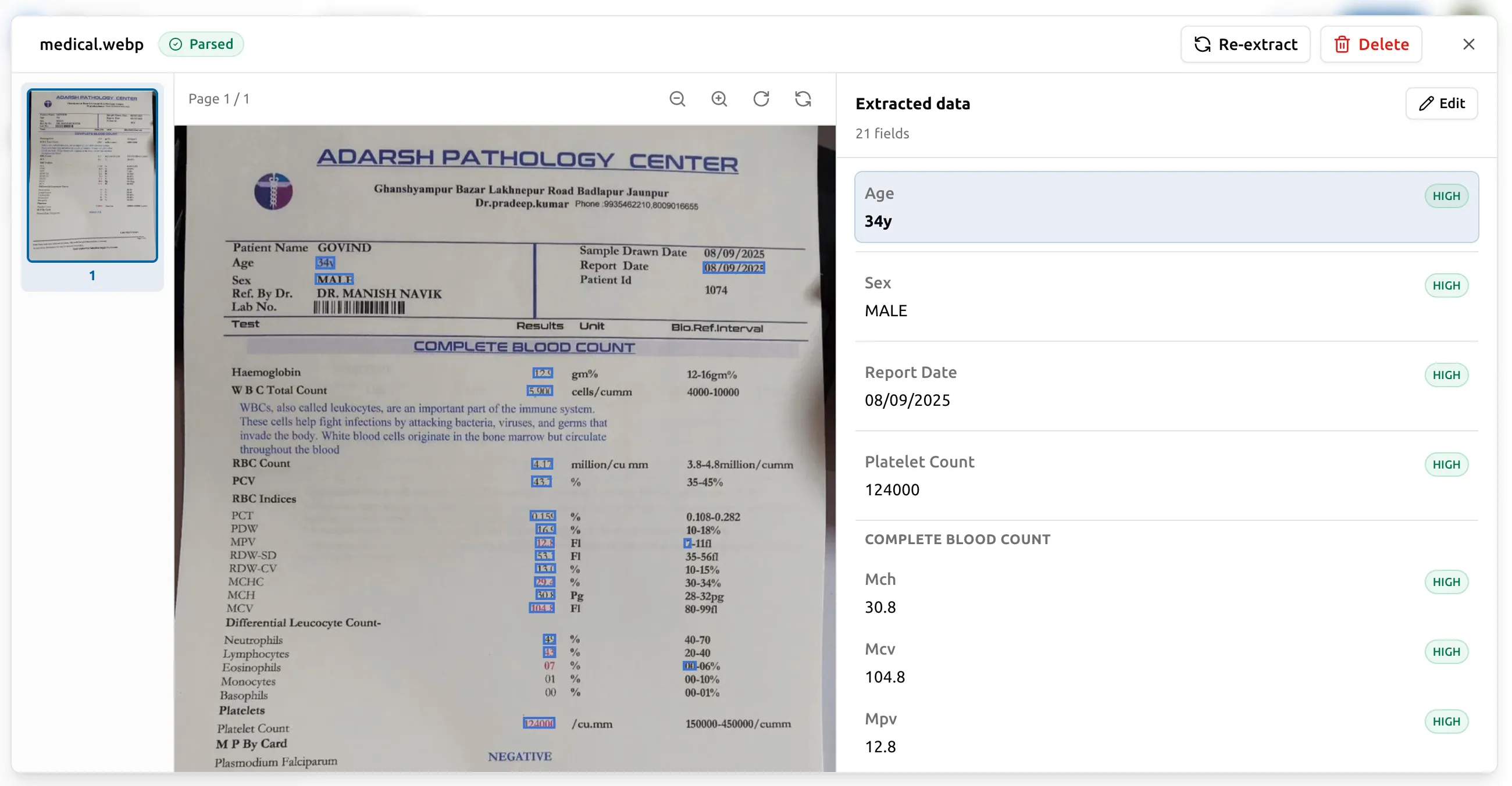
ドキュメントが完了したら、並列ビューアー で開いてください。元の ドキュメントが左側に、抽出されたすべてのフィールドが右側に表示されます。 フィールドをクリックすると、元書類の対応箇所がハイライトされます。 元書類の任意の領域をクリックすると、対応するフィールドが右側でスクロール されて表示されます。
エンジンが自信を持てなかったフィールドには、信頼度スコアで印が付きます。 誤った値を直すには、クリックして正しい値を入力し、保存するだけです。 修正は即座に反映され、再実行の料金はかかりません。次のエクスポートからは 修正後の値が使われます。詳しくは レビューと修正 をご覧ください。
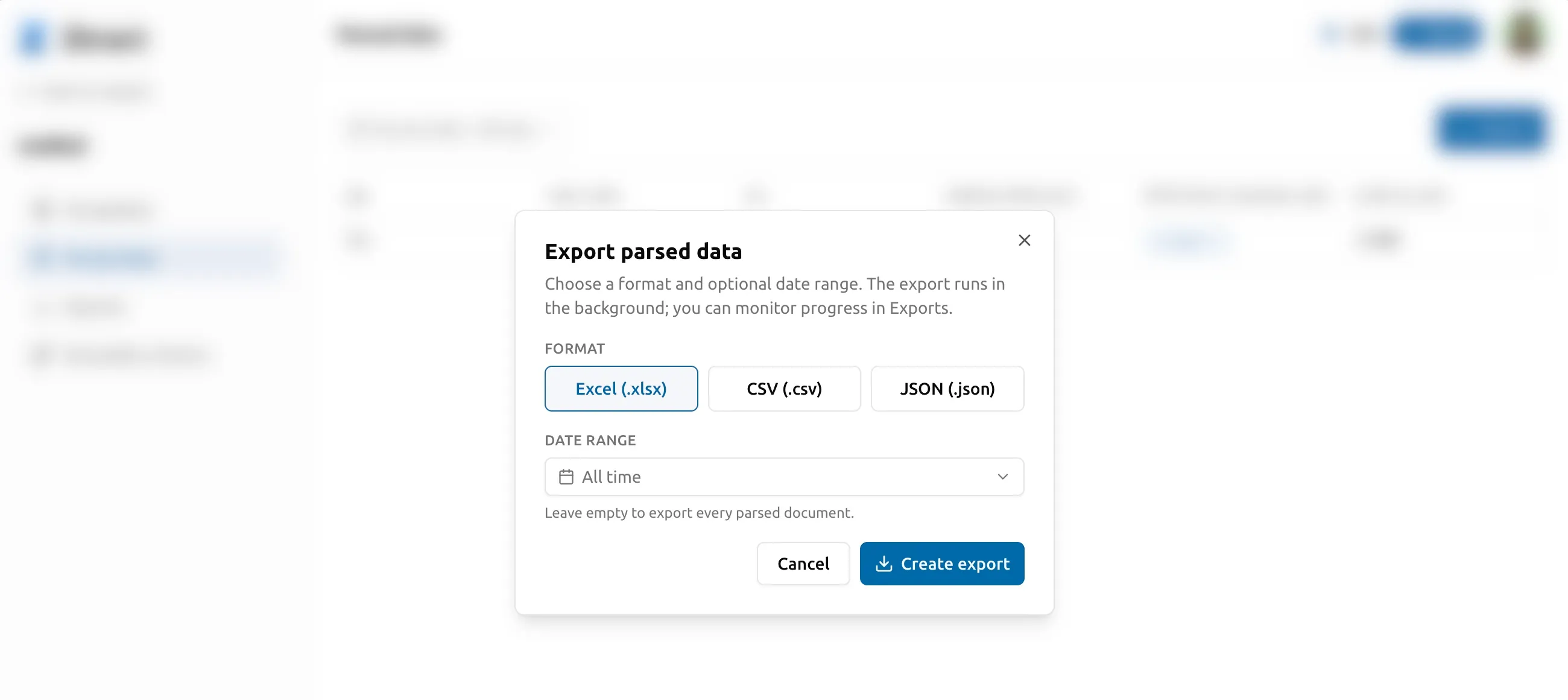
ステップ 6 — エクスポート
データが確認できたら、プロジェクトの 「抽出データ」 タブを開いて 「エクスポート」 をクリックします。Excel、CSV、JSON のいずれかを選び、 必要なら解析日範囲で絞り込み、確定します。エクスポートはバックグラウンドで 実行され、準備が整ったら 「エクスポート」 タブからダウンロードできます。 JSON は完全なネスト構造(当事者、明細行など)を保持します。CSV と Excel は 明細行を別の行またはシートに展開します。お好みのツール — Sheets、Excel、 会計ソフト、データウェアハウス — でファイルを開けば、それで完了です。
初日に知っておくと便利なこと
- ダッシュボードはあなたの言語に対応します。 既定は英語ですが、 右上のアバターメニューから 中文、日本語、한국어、Français、Deutsch、 Español、Português に切り替えられます。スキーマテンプレートも それぞれの言語にローカライズされます。
- 残りページ数はナビゲーションに表示されます。 右上のアンバー色の 「Top up」バッジは、現在のページ残高をリアルタイムで表示し、残りが 少なくなると暖色寄りに変わります。クリックするとパッケージ選択画面に ジャンプします。
- 再抽出にはページが再度消費されます。 ビューアーでフィールドを編集 するのは無料ですが、同じドキュメントに対してエンジンを再実行する場合 (スキーマを変更した、元書類を直した、もう一度きれいに通したいなど)、 通常のページ単価でページが差し引かれます。 レビューと修正 をご覧ください。
次のステップ
30 ページの無料分を使い切ったら、ページパッケージを購入できます — 一括 購入で、12 か月有効、サブスクリプションはありません。仕組みの詳細は 請求、パッケージ、返金 をご覧ください。ご質問があれば、 support@ztract.com までメールしてください。 窓口は 1 つ、チームも 1 つで、営業日 1 日以内に返信します。