レビューと修正
Ztract が単なる OCR サービスと異なる大きな点 — すべての値が出典に紐付き、エンジンは自信のないフィールドを教えてくれ、誤った値は再実行の費用なしに直せます。
更新日:
並列ビューアを開く
ドキュメントの処理が完了したら、プロジェクトのドキュメント一覧で そのドキュメントをクリックしてください。ダッシュボードが 並列ビューア を開きます。左側に元のドキュメント、右側に抽出された フィールドが表示されます。このビューアは、何百回と繰り返す 2 つの 動作のために設計されています。
- 値がページ上の内容と一致していることを確認する。
- 一致していないものを修正する。
フィールドをクリックして出典を見る
右側で抽出されたフィールドをクリックすると、左側の元ドキュメントの 該当領域がハイライトされます。元ドキュメント側の領域をクリックすると、 対応するフィールドが右側でスクロールされて表示されます。これは すべてに対して機能します — スカラーのフィールド、テーブル内の 明細行のセル、複数値配列の個々のチップまで。すべての値には バウンディングボックスが紐付いており、そのバウンディングボックスが フィールドを出典に結び付ける役割を果たします。
複数ページのドキュメント(契約書など)は、元ページが縦に積み上げて 表示されます。7 ページの契約書のうち 6 ページ目に存在するフィールドを クリックすると、ビューアは 6 ページ目までスクロールし、その値が 中央に表示されます。監査や引き継ぎの際に「この数字はどこから来たの?」と 推測する必要はもうありません。
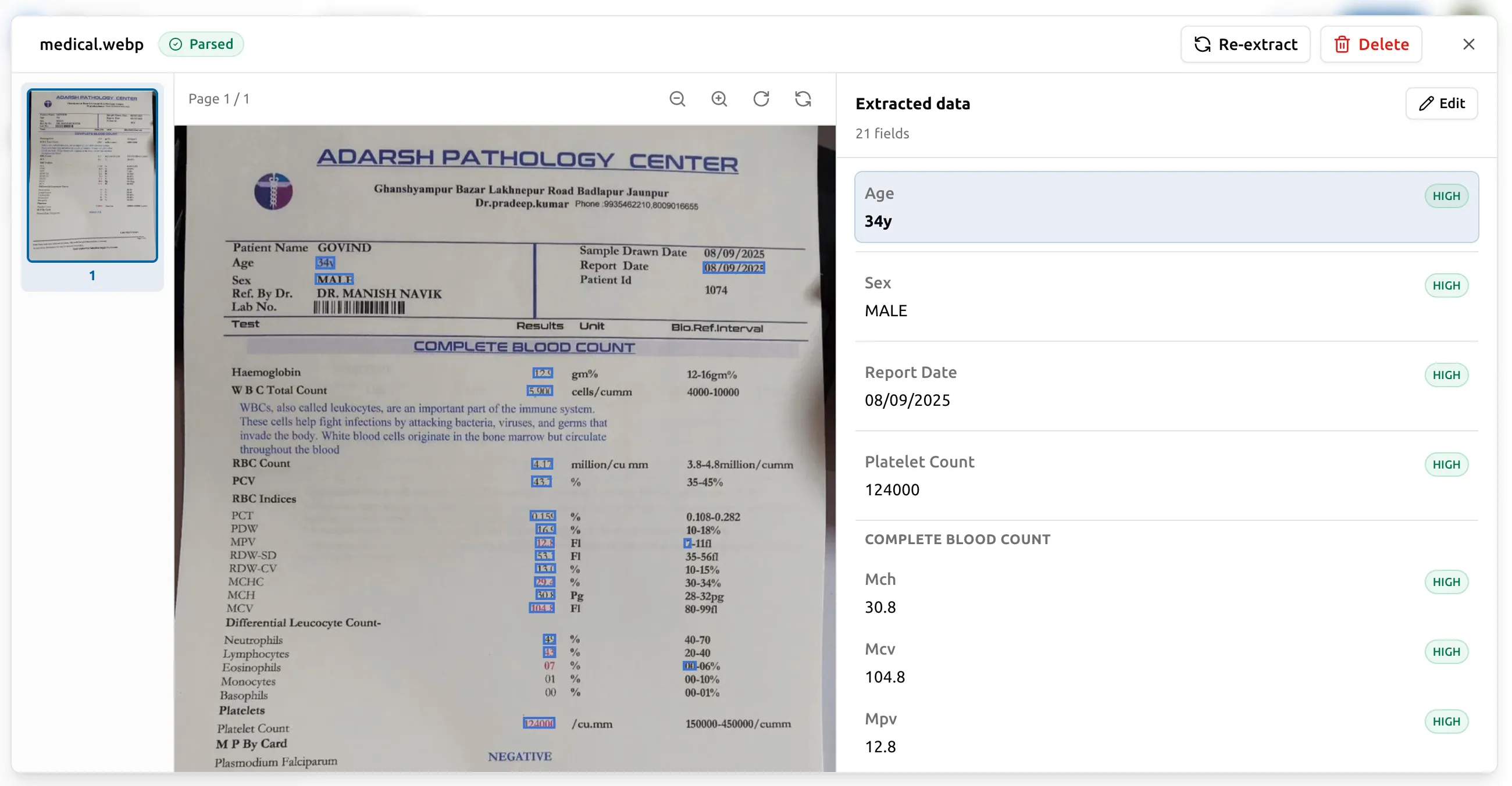
フィールドごとの信頼度スコア
抽出された各値には、エンジンによる信頼度スコアが付与されます。 エンジンが高い信頼度を持つ値(ページ上部に 24 ポイントの文字で 印字された仕入先名など)にはフラグが付きません。エンジンが あまり自信を持てない値(余白に走り書きされた日付、8 か B か 判別しにくい数字など)は視覚的にフラグが付き、どのフィールドを 確認すべきかが一目で分かります。
これが重要なのは、すべてのフィールドで完璧な精度を担保するコストは、 誤りの可能性がある少数を拾い上げるコストよりはるかに高いからです。 信頼度フラグがあれば、出力の 100% を読み直す代わりに、疑わしい 5% を 重点的に確認できます。
誤った値を修正する
編集モードに入るには、抽出データ パネルの上部にある 編集 を クリックします。すべての値がインライン入力欄になります。フラグの 付いたフィールドを順に見ていきましょう。
- フィールドの値をクリックします。
- 正しい値を入力します。
- Enter を押すか、別のフィールドに移動します。
完了したら 保存 をクリックします — パネルのボタンには変更した フィールド数が表示されます(例:「保存 (3)」)。編集を保持せずに 抜けたい場合は キャンセル をクリックします。
修正について知っておくべき 3 つのこと。
- 再実行の費用は発生しません。 フィールドを編集してもエンジンは 再呼び出しされません。元の抽出結果の上に、ドキュメントごとの オーバーレイを書き加えているだけです。無料です。
- 元のバウンディングボックスは修正後の値にそのまま紐付いたまま です。 監査担当者から「この数字はどこから来たのか」と問われても、 並列ビューアは引き続き元ドキュメントの該当領域を示します。
- 修正は永続化されます。 再エクスポート、スキーマ編集、アカウントの セッションをまたいでも維持されます。来週同じフィールドを直し直す 必要はありません。
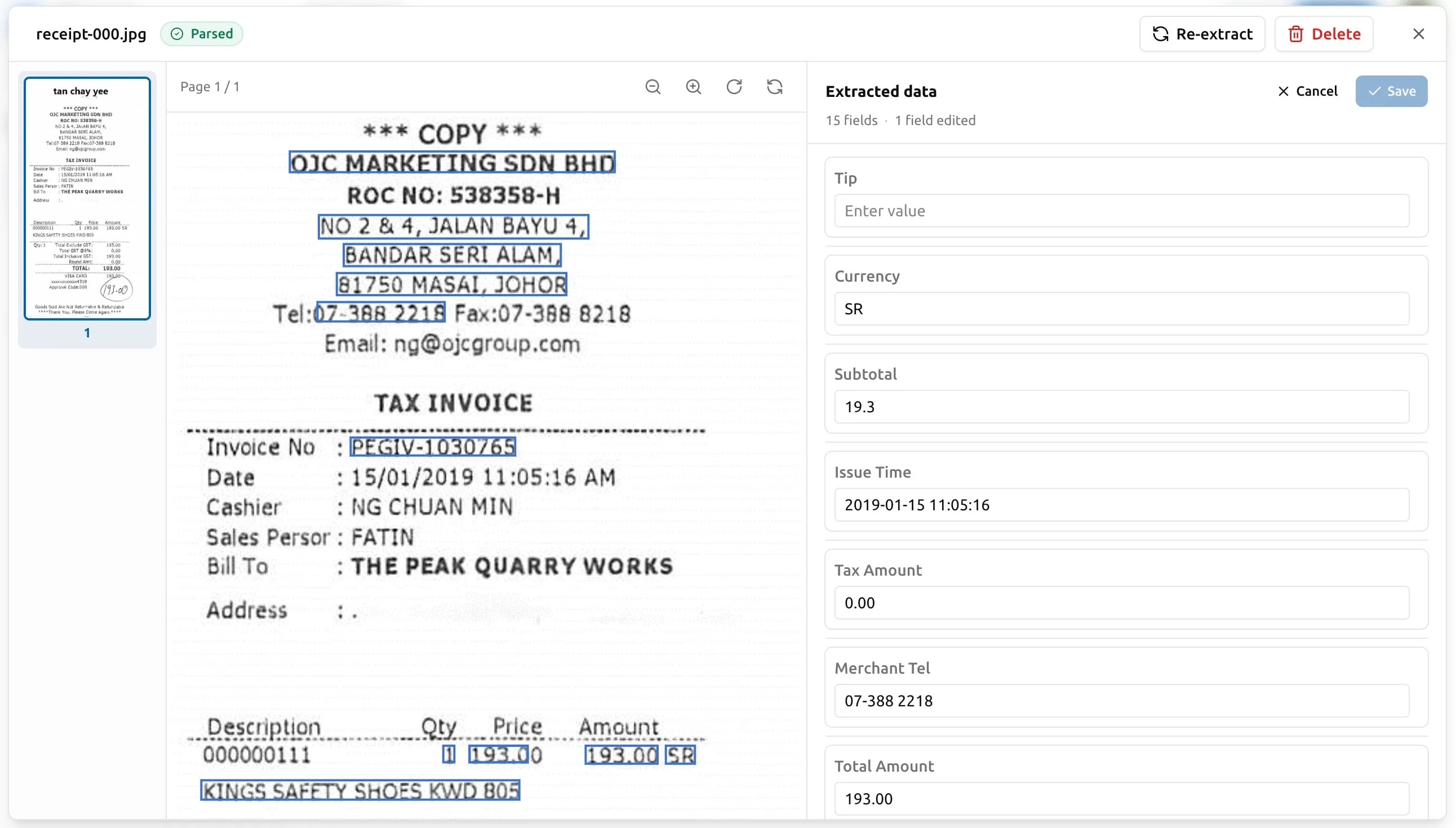
編集を取り消す
編集されたフィールドには、パネル内に小さな鉛筆バッジが表示されます。 取り消す方法は 2 つあります。
- トップレベルのフィールドごと:パネルでそのフィールドのヘッダーを 開き、元に戻す をクリックします — そのフィールドだけ、エンジンが 返した元の値に戻ります。
- この抽出結果のすべての編集:パネル上部の すべての編集をクリア を クリックします。
どちらの操作も即時に反映され、次のエクスポートにも反映されます。
修正で行われないこと
修正はドキュメントごとのオーバーライドです。次のことは しません。
- ドキュメントの元ファイルは変更しません(PDF や画像はストレージ上で 不変です)。
- 次のドキュメントでエンジンの挙動を変えるよう指示することはありません。 多数のドキュメントで同じフィールドを直し続けている場合は、修正ではなく スキーマやドキュメント品質が見直すべきレバーです。
- 抽出の再実行を引き起こしません。別のスキーマで新しい抽出が必要な 場合は、次のセクションをご覧ください。
別のスキーマで再実行する
ドキュメントの処理後にスキーマを変更すると、既存の抽出結果は古い スキーマのままです。影響を受けたドキュメントには、ドキュメント 一覧でアンバー色の スキーマ更新済み バッジが付き、詳細ダイアログの 上部にも同じヒントが追加されるので、一目で見分けられます。
新しい形に揃えるには、そのドキュメントを新しいスキーマで再実行 します。選択肢は 2 つあります。
- 1 件ずつ再実行する。 該当行の
⋯メニューを開いて 再抽出 を選ぶか、詳細ダイアログ内の同じアクションを使います。 ワーカーが拾い上げる間、ステータスは一旦「保留中」に戻ります。 ダイアログはポーリングして自動的に更新されます。 - 古いドキュメントを一括で再実行する。 ドキュメント一覧の上部に ある 古い文書を再抽出 ボタンで、プロジェクト内のフラグが付いた すべてのドキュメントを再実行します。ダイアログは確定前にページの 消費量を表示します。
再実行では ページが消費されます — エンジンを通すたびに、初回と 同じ 1 ページあたりの単価でページが差し引かれます。そのため、多くの チームは本格的な処理に進む前に、小さなバッチ(たとえば 5〜10 件)で スキーマを確定させています。サンプルでフィールド名、ネスト構造、 型を整えてから、処理量を増やしましょう。
失敗したページ
初回抽出時にページが失敗した場合、ダッシュボードは失敗理由とともに 表示します。次の対応が可能です。
- 元ファイルを再アップロード する(例:パスワード保護を解除した、 元のツールから PDF を出力し直したなど、原因を解消した場合)。
- スキップ する(解決する価値がない場合)。
失敗したページはパックに払い戻されます — エンジンが読み取れなかった ものに対して課金されることはありません。