审核与改正
Ztract 跟普通 OCR 服务最大的区别:每个值都锚定回源文档、引擎会主动告诉你哪些字段它没把握,而你改错值不用再付一次钱。
更新于:
打开并排查看器
一份文档处理完之后,在项目的文档列表里点它一下,dashboard 会 打开并排查看器:原文档在左边,抽出的字段在右边。这个查看器 是为你会重复成百上千次的两个动作设计的:
- 确认某个值跟页面上的内容一致。
- 改掉不对的那个。
点一个字段,看它来自哪里
点右边任意一个抽出的字段,左边源文档上对应的区域立刻高亮。 反过来,点源文档上的某块区域,对应字段会滚动到右边视野里。 所有东西都能这么用 —— 标量字段、表格里的明细行单元格、多值 数组里的单个 chip 都行。每个值都有一个 bounding box,正是这个 bounding box 把字段锚定回了它的来源。
多页文档(比如合同)会把源页面纵向堆叠。点一个落在 7 页合同 的第 6 页上的字段,查看器会滚动到第 6 页,并把值居中显示。 审计或者交接时,再也不用对着数字猜「这个数到底是哪儿来的」。
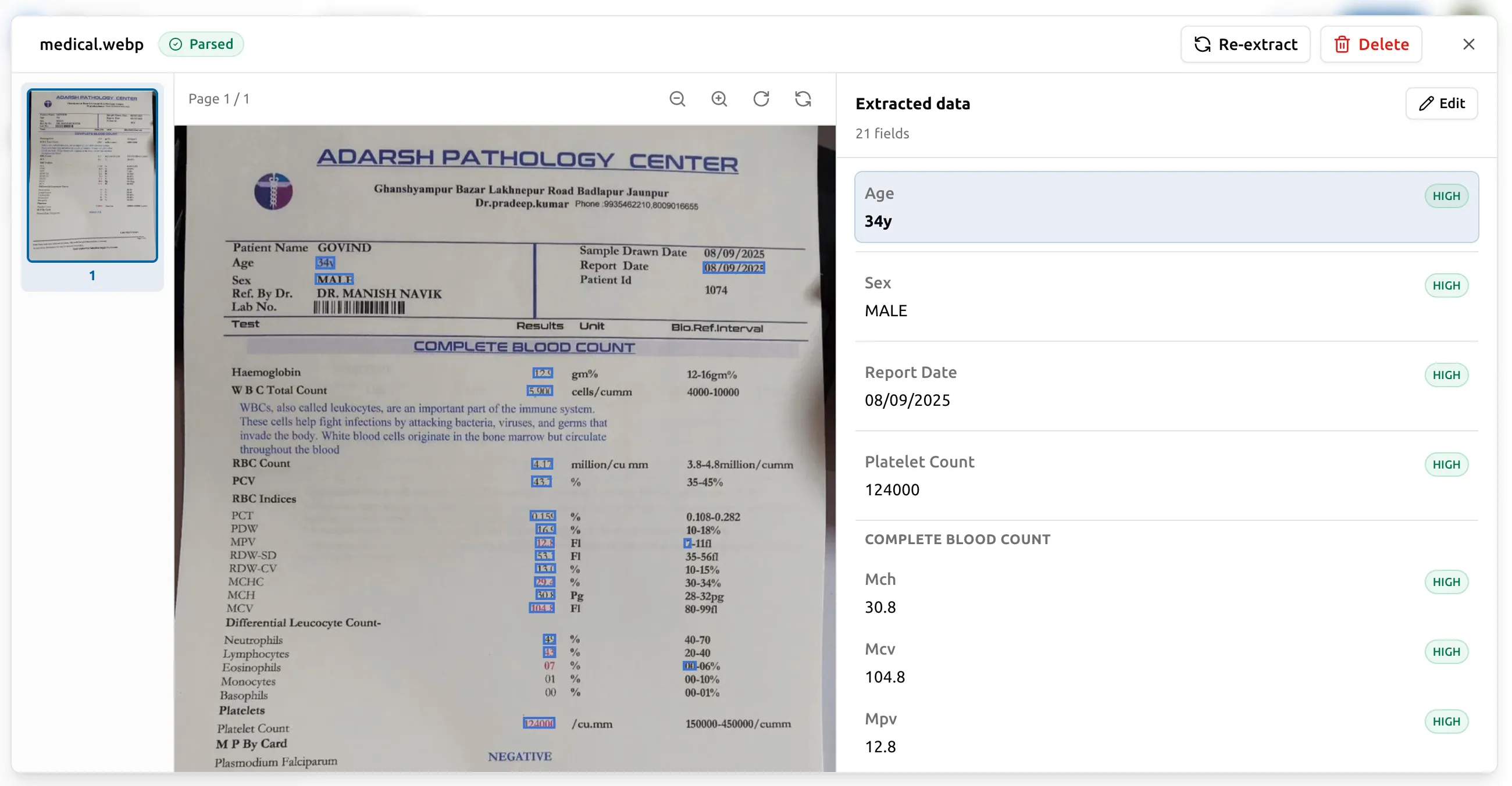
逐字段置信度
每个抽出的值都带一个引擎给出的置信度分数。引擎非常有把握的值 (比如页面顶部用 24 号字印出来的供应商名称)不会被标记。引擎 没那么有把握的值(页边随手潦草写的日期、可能是 8 还是 B 的 数字)会被显眼地标出来,这样你能一眼看出该重点核对哪些字段。
这件事很重要,因为「每个字段都做到完美准确」的成本,远高于 「把可能出错的少数几个挑出来」的成本。置信度标记让你只抽查 那 5% 可疑的,不用 100% 重读所有输出。
改正错值
点抽取数据面板顶部的编辑,进入编辑模式。每个值都会 变成行内输入框。把被标记的字段挨个过一遍:
- 点字段的值。
- 输入正确的内容。
- 按回车,或者切到下一个字段。
改完之后,点保存 —— 面板上的按钮会显示你改了多少个字段, 例如 “保存 (3)“。不想保留改动就走,点取消。
关于改正,有三件事要知道:
- 你不用为重跑付费。 你编辑字段时引擎并没有被重新调用; 你只是在原始抽取结果上叠了一层逐文档的覆盖层。免费。
- 原来的 bounding box 还挂在改正后的值上。 如果审计的人问 「这个数是哪儿来的」,并排查看器依然能指到源文档上正确的区域。
- 改正会持久保留。 它能挺过重新导出、schema 编辑和账号 登退。下周你不用再把同一个字段改一遍。
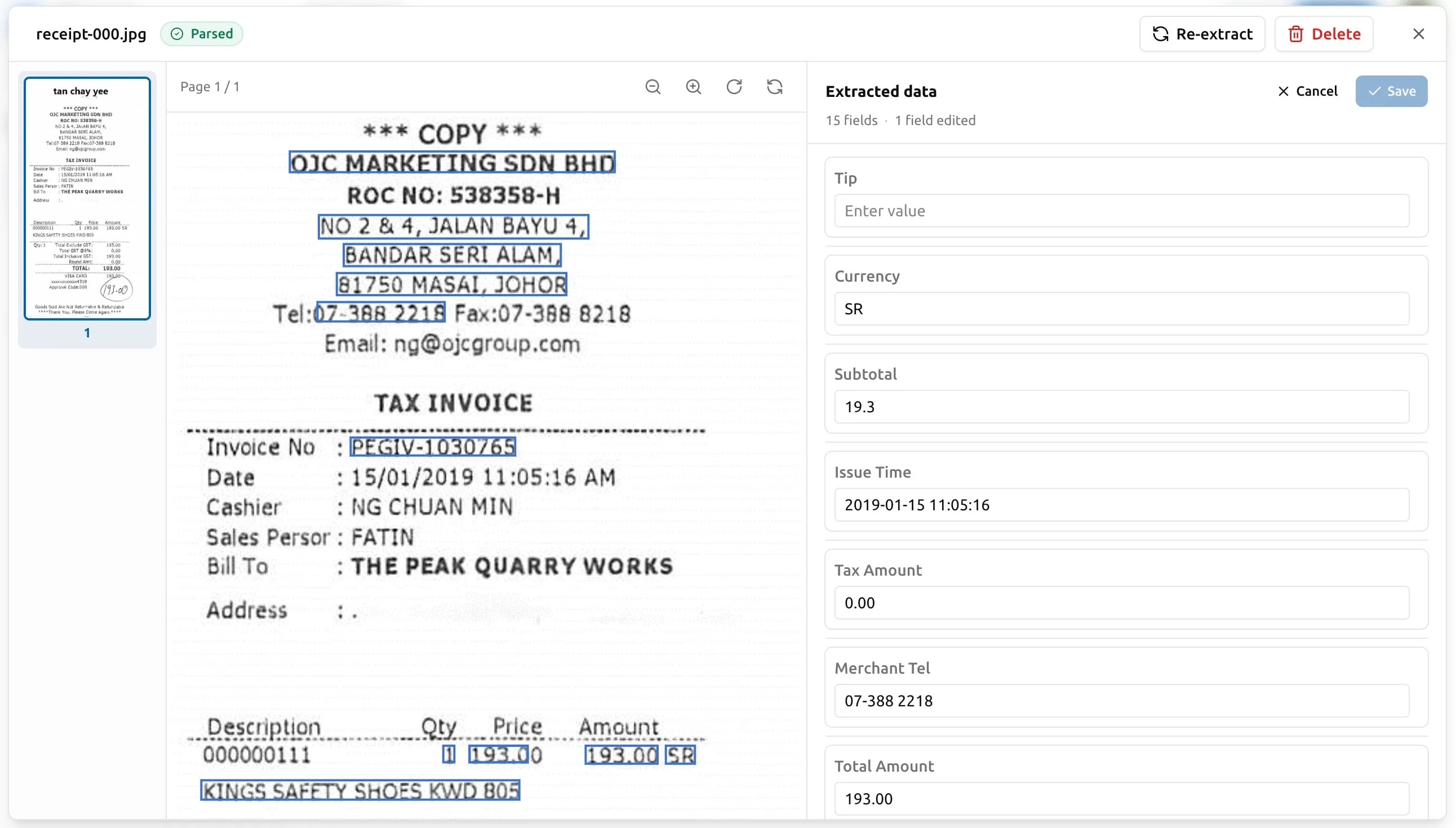
撤销一次编辑
被编辑过的字段会在面板里带一个小铅笔标记。撤销有两种方式:
- 针对单个顶层字段:在面板里打开这个字段的标题区,点 撤销 —— 引擎原来的值会回到这一个字段。
- 撤销这次抽取的所有编辑:点面板顶部的清除所有编辑。
两种操作都即时生效;下一次导出会反映这个状态。
改正做不到的事
改正是一份逐文档的覆盖。它不会:
- 改动文档的源文件(PDF 和图片在存储里是不可变的)。
- 让引擎在下一份文档上做出任何不同的事。如果你发现自己在 很多文档上一直在改同一个字段,那要动的是 schema 或者文档 质量,不是改正。
- 触发一次重新抽取。如果你想用一份不同的 schema 拿到新结果, 看下一节。
用不同的 schema 重跑
如果你在一份文档处理完之后改了 schema,原来的抽取结果反映的 还是旧 schema。受影响的文档会在文档列表里被打上一个琥珀色的 schema 已更新标记,详情对话框顶部也会加上同样的提示, 方便你一眼看到。
要拿到新结构的结果,你需要把这份文档对着新 schema 重跑一遍。 两种选择:
- 一份一份来。 打开那一行的
⋯菜单,选重新抽取, 或者在详情对话框里用同一个操作。状态会切回 pending,等 worker 接手;对话框会自动轮询并更新。 - 一次性把所有过期的都重跑。 文档列表顶部的重新抽取 过期文档按钮,会把项目里所有被标记的文档全部重跑。在你 确认之前,对话框会告诉你要花多少页。
重跑是要扣页数的 —— 每过一次引擎,都按跟首次抽取一样的 每页费率扣费。正因为这样,大多数团队会先在一小批文档上 (比如 5–10 个文档)把 schema 定稿,再上量。先在样本上把 字段名、嵌套结构和类型都搞对,然后再放量。
失败的页面
如果某一页在初次抽取时失败了,dashboard 会显示失败原因。 你可以:
- 重新上传源文件,前提是你已经修过了(比如去掉了密码 保护、用原工具重新导出了 PDF)。
- 跳过它,如果不值得花精力解决。
失败的页面会退回到你的页数包里 —— 引擎读不出来的内容,你 不用付钱。