








01
Generalizes across layouts
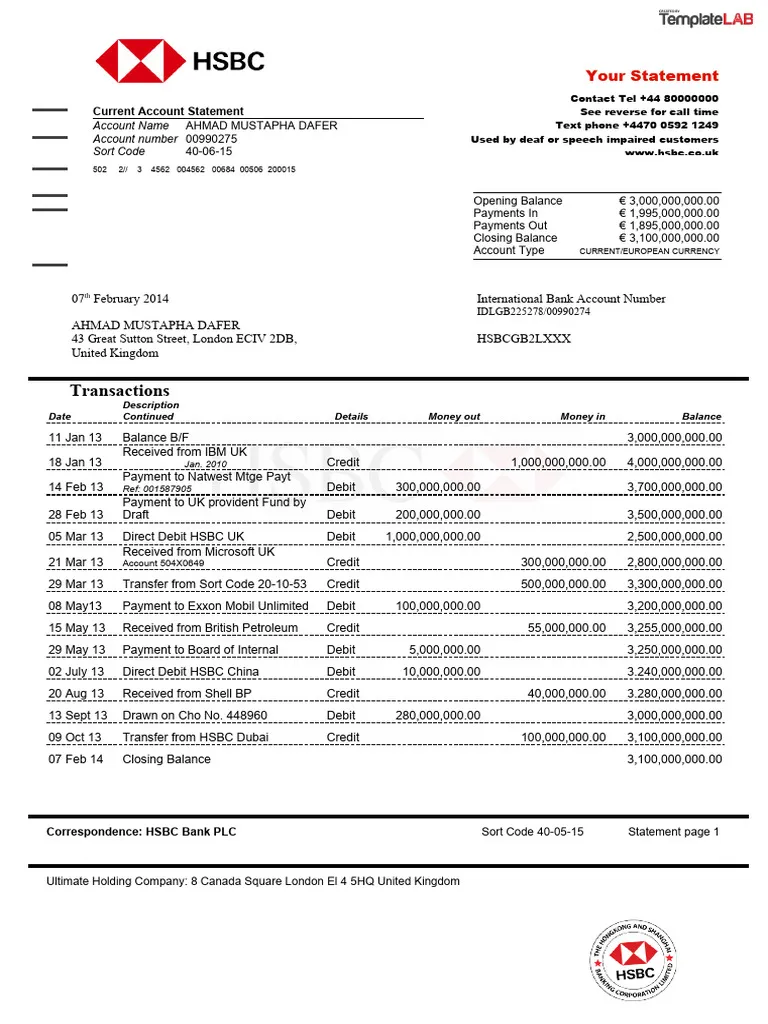
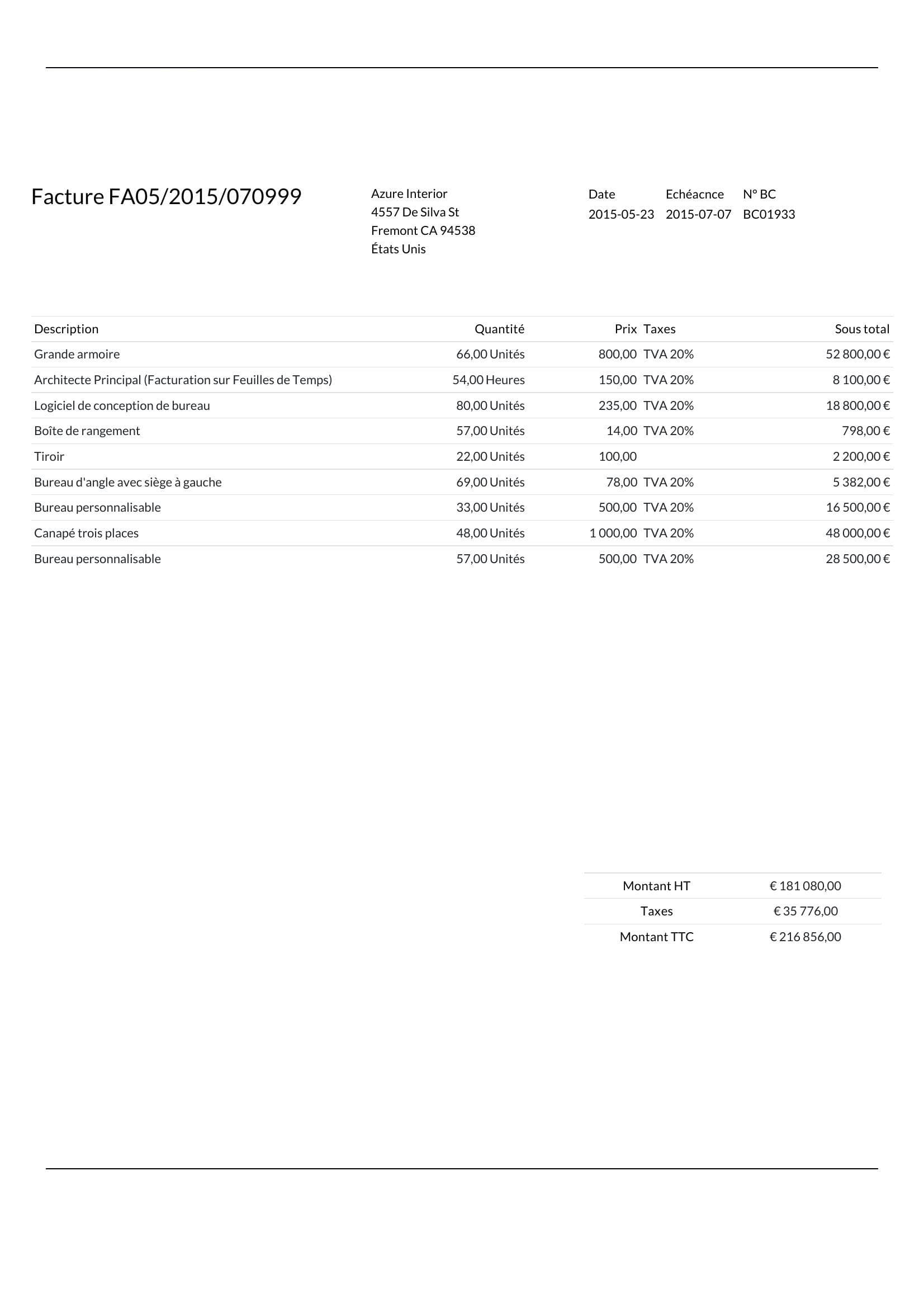
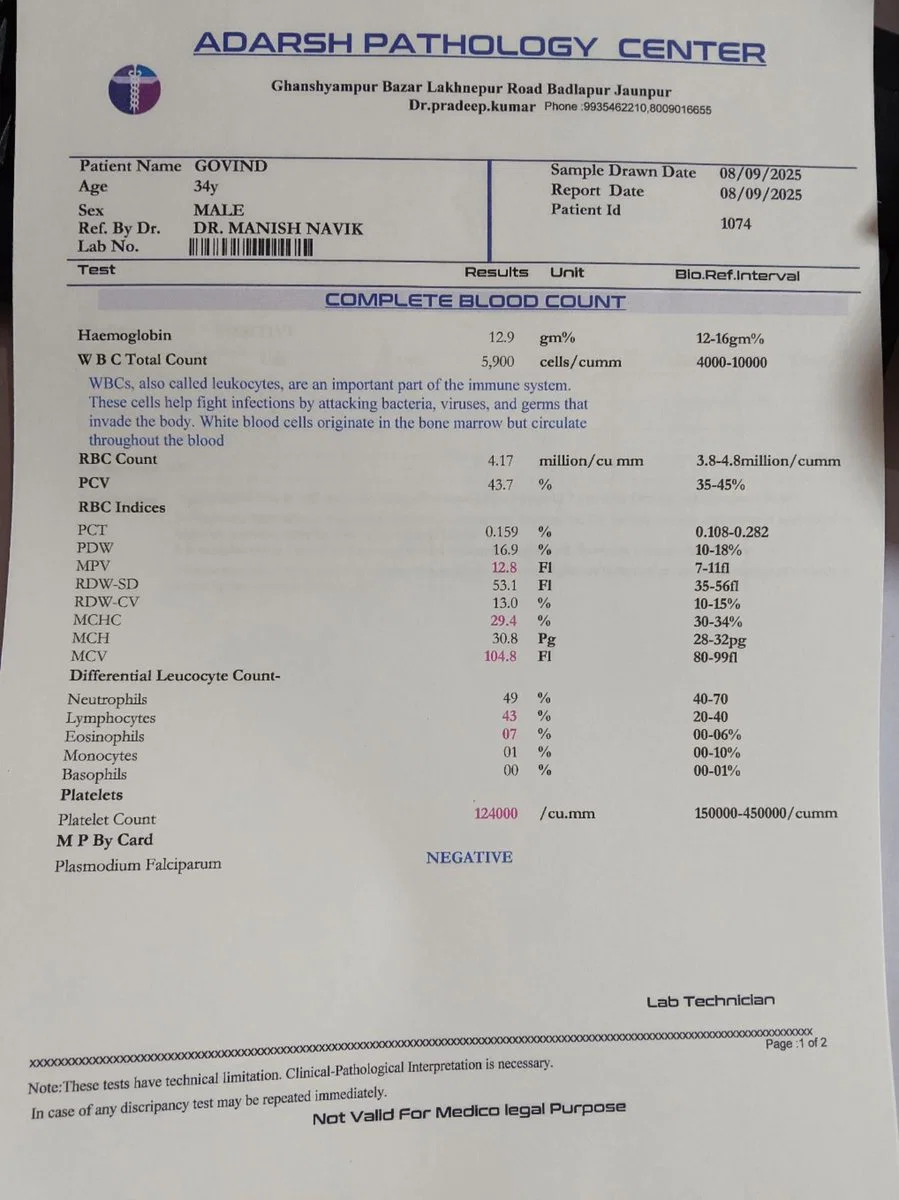
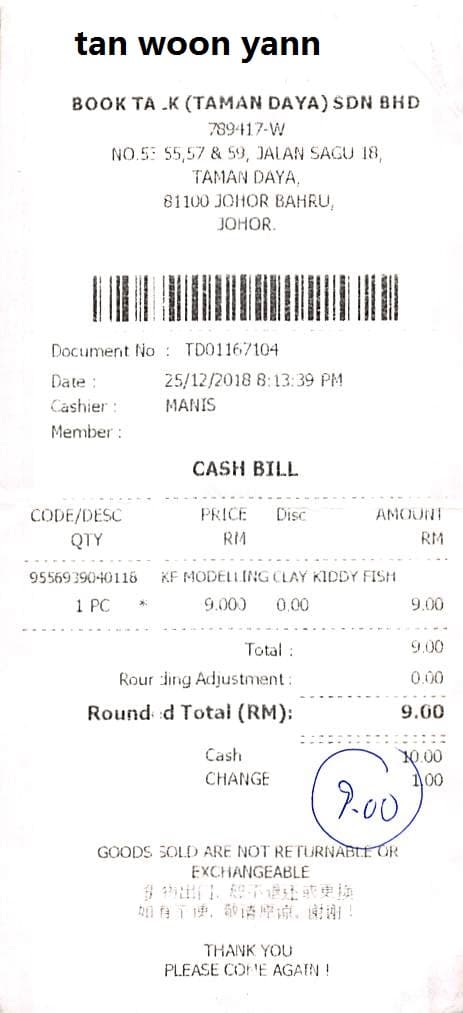
A new vendor invoice works the first time, without you adding a template or a rule. The engine learns layout from the document itself.
- Cross-page table merging
- Form-field detection without templates
- Same schema, hundreds of layouts


